We announced our new literature-focused features in our last blog post. One of the unique features of our approach is that we use deep learning concepts, a subset of machine learning, to text mine literature. A characteristic of deep learning is that various characteristics, or attributes, of a paper can be extracted.
One of the characteristics we identify is whether a piece of literature is supportive, contradictory or inconclusive in its support for the probabilistic correlation between a biomarker and a disease state. We take that a step further and look at whether a biomarker is actively measured in the piece of literature’s description of the related experiments.
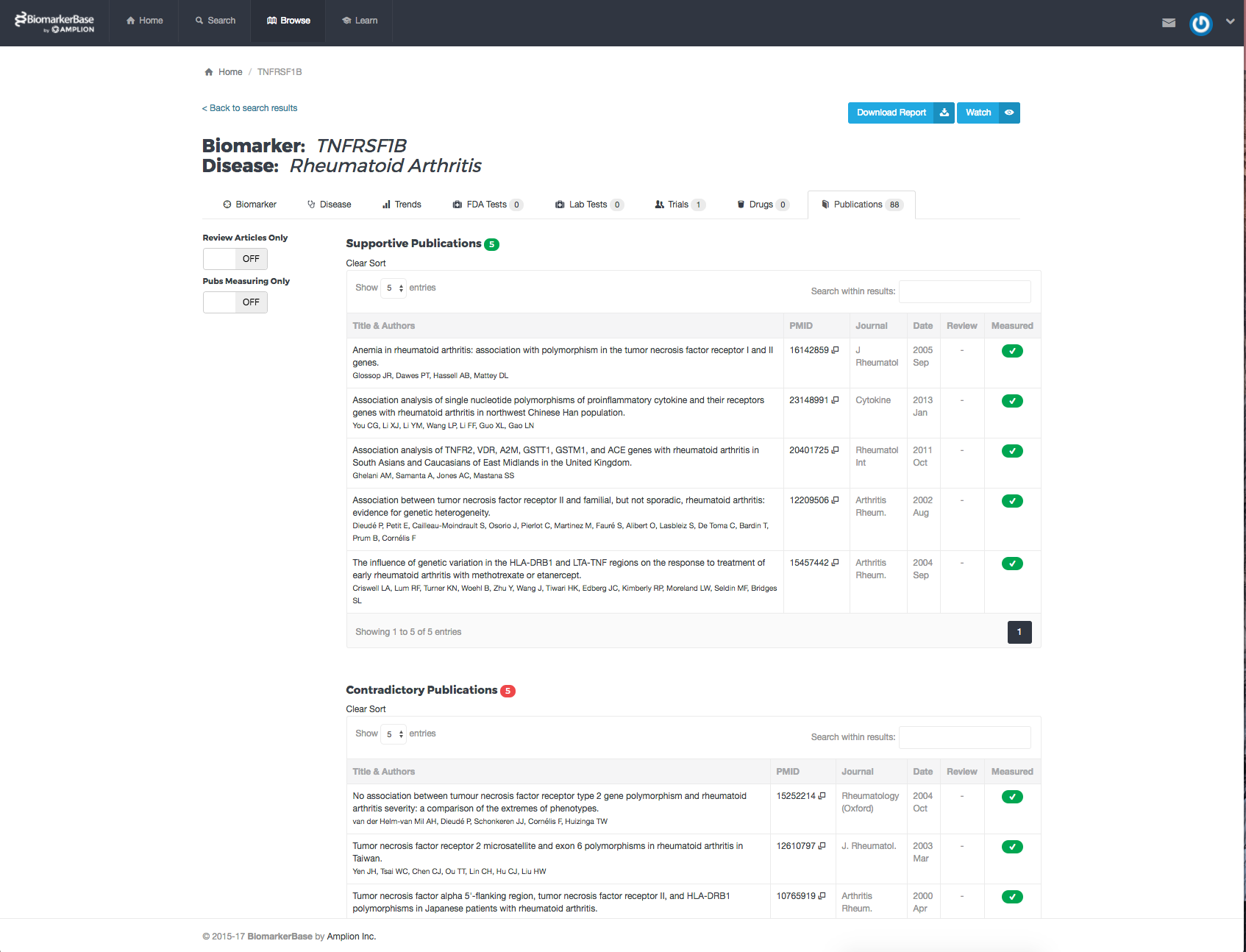
So, for each biomarker you can review the literature for a correlated disease state and prioritize your reading schedule based on the supportive or contradictory nature of the paper. For some more recent biomarkers, there might not be clear supportive or contradictory literature. In those cases, the inconclusive and co-mentioned papers are available to get an idea.
Now, we can focus on biomarkers not found in a clinical setting and prioritize them by publications.
However, many users like to see the combination of clinical and pre-clinical work to make informed decisions for biomarker strategic planning.
With different sorting BiomarkerBase users can prioritize clinical work while still reaping the benefits of advanced publication prioritization.
When reviewing any biomarker the user will be presented with a list of publications organized by those that support the biomarker-disease usage, contradict the biomarker-disease usage, or don’t provide a clear conclusion.